大数据框架简介
可以参照这篇文章:大数据架构:flume-ng+Kafka+Storm+HDFS 实时系统组合
Kafka 简介
Kafka 综述
Kafka 是一个分布式发布订阅消息系统。对于网页中的流动数据(页面访问量、搜索情况等),通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。
Kafka 架构设计
我们将消息的发布(publish)称作 producer,将消息的订阅(subscribe)表述为 consumer,将中间的存储阵列称作 broker,这样我们就可以大致描绘出这样一个场面: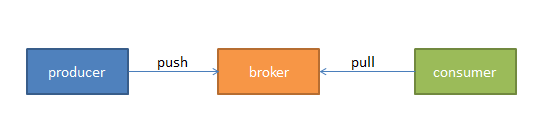
生产者将数据生产出来,丢给 broker 进行存储,消费者需要消费数据了,就从broker中去拿出数据来,然后完成一系列对数据的处理。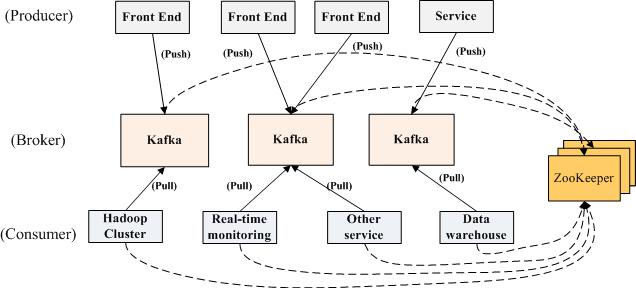
多个 broker 协同合作,producer 和 consumer 部署在各个业务逻辑中被频繁的调用,三者通过 zookeeper 管理协调请求和转发。这样一个高性能的分布式消息发布与订阅系统就完成了。图上有个细节需要注意,producer 到 broker 的过程是 push,也就是有数据就推送到 broker,而 consumer 到 broker 的过程是 pull,是通过 consumer 主动去拉数据的,而不是 broker 把数据主动发送到 consumer 端的。这样就能一定程度上缓解 producer 和 consumer 之间对资源竞争的冲突,像一种异步通信方式。
主题和日志
Topics(主题)是 Kafka 中的一个高级抽象概念,producer 向某个确定的 Topic 发布消息,对应地,consumer 也向某个确定的 Topic 订阅消息。对于每个 topic,Kafka 会维护一个如下所示的日志分组队列:
新的日志都直接加在每个消息队列的最后,通过一个 Offset 偏移量来访问每一条日志信息。并且我们可以设置一个过期时间,超过一般为两天为限,就会把这些没有被消费的日志清楚,释放空间。
Reference Here.
快速入门
运行环境
操作系统:CentOS 6.5(64位)(VMware 虚拟机)
JDK 版本:1.7.0_79(对 1.8 的支持可能存在一些问题,建议 1.7 即可)
Kafka版本:0.8.2.1,我下载的是带有 Scala 的二进制文件,较为便捷。kafka_2.11-0.8.2.1.tgz,截止当前为最新稳定版。
准备工作
JDK
假设 JDK 环境配置已经完成,如果还没有配置,请参看 这里。
解压缩
tar -xzf kafka_2.11-0.8.2.1.tgz |
cd kafka_2.11-0.8.2.1.tgz |
运行服务器
Kafka 使用 ZooKeeper 作为服务器,这在我们下载的包中已经有一个单节点的 ZooKeeper 服务实例。
bin/zookeeper-server-start.sh config/zookeeper.properties |
[2015-07-23 16:26:01,356] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig) |
运行 Kafka 服务器,
bin/kafka-server-start.sh config/server.properties |
连接失败了,但是不用担心,我们需要使用 sudo 权限!本地测试时,如果仅仅使用 sudo 会提示 exec: java: not found 的异常,所以请使用 su 进入超级用户模式,以后的其他操作也请在超级模式,使用 ‘#’ 作为提示符。
终于,两边分别有提示连接成功的输出:
# Zookeeper Server部分 |
创建Topic
我们首先创建一个只有一个 Broker 分组、只有一个副本的话题,test
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test |
bin/kafka-topics.sh --list --zookeeper localhost:2181 |
list命令提示test,说明创建成功。
发送消息
我们在 test 这个主题下,使用 Producer 发送一些消息
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test |
输入一些消息,下面我们创建 Consumer 来消费。这里的一些参数可以通过输入
bin/kafka-console-producer.sh |
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning |
我们得到如下信息,表明信息的发布和订阅都成功了~!
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test |
单机版的多 Broker 方式
两台服务器
我们假设有两台服务器,使用不同的端口进行连接。首先我们先为每一个 broker 建立一个服务器的配置文件
cp config/server.properties config/server-1.properties |
分别在这些文件中修改为如下内容:
config/server-1.properties: |
此时我们运行 Kafka 的两台服务器,’&’ 表示可以在后台运行
bin/kafka-server-start.sh config/server-1.properties & |
# server-1, 被选为leader |
创建新的话题
创建一个新的话题,叫做 multitest,注意这里的 --replication-factor 参数,表示了 server 的个数,不能超过当前的所有 running 的服务器个数。(加上前面的一共有三个,这里 1,2,3 都是可以的,但是 >=4 不行)
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 1 --topic multitest |
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic multitest |
新的 Producer 和 Consumer
同上建立新的 Producer 发布消息日志,
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic multitest |
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic multitest |
检测容错的机制
我们现在关闭 server-1
ps | grep server-1.properties |
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic multitest` |
如果此时再开启一个 Consumer ,仍然可以得到原本完整 4 条消息的日志。
其他
其他完整且详细的资料请参看 kafka系列文章,本文也同时参考了 Apache Kafka 的官方文档。