概述 HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用 HBase 技术可在廉价 PC Server 上搭建起大规模结构化存储集群。HBase可以依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
大:一个表可以有上亿行,上百万列
面向列:面向列(族)的存储和权限控制,列(族)独立检索。
稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase数据模型 Table & Column Family 最简单且基本的HBase中的数据主要是按照如下格式进行存储的:
Row Key: 行键,Table 的主键,Table 中的记录按照 Row Key 的【字典序】排序
Timestamp: 时间戳,每次数据操作对应的时间戳,可以看作是数据的 version number
Column Family:列簇,Table 在水平方向有一个或者多个 Column Family 组成,一个 Column Family 中可以由任意多个 Column 组成,即 Column Family 支持动态扩展,无需预先定义 Column 的数量以及类型,所有 Column 均以二进制格式存储,用户需要自行进行类型转换。
Cell:由 {row key, column( =family + label), timestamp} 唯一确定的单元。cell 中的数据是没有类型的,全部是字节码形式存贮。
Table & Region 当Table随着记录数不断增加而变大后,当达到一个设定阈值时,会逐渐分裂成多份 splits,成为 regions,一个 region 由 [startkey,endkey) 表示,不同的 region 会被 Master 分配给相应的 RegionServer 进行管理。HTable 将根据行被拆分为 HRigion 进行管理,而当某个 HRigion 过大时,又会自动分解为多个 HRigion 来维护数据,HRigion是这里分布式存储和负载均衡的最小单元。不同的 Hregion 可以分布在不同的 HRegion server 上,但一个 Hregion 是不会拆分到多个 server 上的。
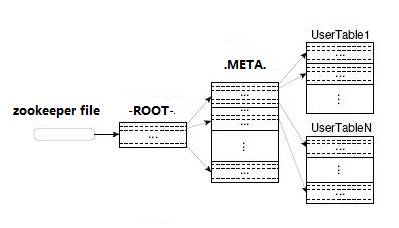
HBase 中有两张特殊的 Table,-ROOT- 和 .META.
.META.:记录了用户表的 Region 信息,.META. 可以有多个 regoin
-ROOT-:记录了 .META. 表的 Region 信息,-ROOT- 只有一个 region
Zookeeper 中记录了 -ROOT- 表的 location
Client访问用户数据之前需要首先访问 zookeeper,然后访问 -ROOT- 表,接着访问 .META. 表,最后才能找到用户数据的位置去访问,中间需要多次网络操作,不过 client 端会做 cache 缓存。HBase技术介绍
关键算法和流程 Region 定位 系统如何找到某个 row key (或者某个 row key range)所在的 region? bigtable 使用三层类似 B+ 树的结构来保存 region 位置。
第一层是保存 zookeeper 里面的文件,它持有 root region 的位置。
第二层 root region 是 .META. 表的第一个 region 其中保存了 .META.z 表其它 region 的位置。通过 root region,我们就可以访问 .META. 表的数据。
.META. 是第三层,它是一个特殊的表,保存了 HBase 中所有数据表的 region 位置信息。
说明:
root region 永远不会被 split,保证了最多需要三次跳转,就能定位到任意region。
.META. 表每行保存一个 region 的位置信息,row key 采用表名+表的最后一样编码而成。
为了加快访问,.META. 表的全部 region 都保存在内存中。假设,.META. 表的一行在内存中大约占用 1KB。并且每个 region 限制为 128MB。那么上面的三层结构可以保存的 region 数目为:$(128MB/1KB) \times (128MB/1KB) = 2^{34}$ 个 region
client 会将查询过的位置信息保存缓存起来,缓存不会主动失效,因此如果 client 上的缓存全部失效,则需要进行 6 次网络来回,才能定位到正确的 region(其中三次用来发现缓存失效,另外三次用来获取位置信息)。
读写过程 上文提到,HBase 使用 MemStore 和 StoreFile 存储对表的更新。
写请求处理过程
client 向 region server 提交写请求
region server 找到目标region
region 检查数据是否与 schema 一致
如果客户端没有指定版本,则获取当前系统时间作为数据版本
将更新写入 WAL log
将更新写入 Memstore
判断 Memstore 的是否需要 flush 为 Store 文件
region 分配 任何时刻,一个 region 只能分配给一个 region server。master 记录了当前有哪些可用的 region server。以及当前哪些 region 分配给了哪些 region server,哪些 region 还没有分配。当存在未分配的 region,并且有一个 region server 上有可用空间时,master 就给这个 region server 发送一个装载请求,把 region 分配给这个r egion server。region server 得到请求后,就开始对此 region 提供服务。
region server 上线 master 使用 zookeeper 来跟踪 region server 状态。当某个 region server 启动时,会首先在 zookeeper 上的 server 目录下建立代表自己的文件,并获得该文件的独占锁。由于 master 订阅了 server 目录上的变更消息,当 server 目录下的文件出现新增或删除操作时,master 可以得到来自 zookeeper 的实时通知。因此一旦 region server 上线,master 能马上得到消息。
region server 下线 当 region server 下线时,它和 zookeeper 的会话断开,zookeeper 而自动释放代表这台 server 的文件上的独占锁。而 master 不断轮询 server 目录下文件的锁状态。如果 master 发现某个 region server 丢失了它自己的独占锁,(或者 master 连续几次和 region server 通信都无法成功),master 就是尝试去获取代表这个 region server 的读写锁,一旦获取成功,就可以确定:
region server 和 zookeeper 之间的网络断开了。
region server 挂了。
的其中一种情况发生了,无论哪种情况,region server 都无法继续为它的 region 提供服务了,此时 master 会删除 server 目录下代表这台 region server 的文件,并将这台 region server 的 region 分配给其它还活着的同志。
master 上线 master 启动进行以下步骤:
从 zookeeper 上获取唯一一个代码 master 的锁,用来阻止其它 master 成为 master 。
扫描 zookeeper 上的 server 目录,获得当前可用的 region server 列表。
和2中的每个 region server 通信,获得当前已分配的 region和region server 的对应关系。
扫描 .META.region 的集合,计算得到当前还未分配的 region,将他们放入待分配 region 列表。
master 下线 由于 master 只维护表和 region 的元数据,而不参与表数据 IO 的过程,master 下线仅导致所有元数据的修改被冻结(无法创建删除表,无法修改表的 schema,无法进行 region 的负载均衡,无法处理 region 上下线,无法进行 region 的合并,唯一例外的是 region 的 split 可以正常进行,因为只有 region server 参与),表的数据读写还可以正常进行。因此 master 下线短时间内对整个 HBase 集群没有影响。从上线过程可以看到,master 保存的信息全是可以冗余信息(都可以从系统其它地方收集到或者计算出来),因此,一般 HBase 集群中总是有一个 master 在提供服务,还有一个以上的 “master” 在等待时机抢占它的位置。NoSQL:列存储数据库之HBase介绍
快速入门 运行环境 操作系统:CentOS 6.5(64位)(VMware 虚拟机)1.7.0_79 (对 1.8 的支持可能存在一些问题,建议 1.7 即可,而 1.6 则可能不支持)1.0.1.1 ,请选择稳定版!
准备工作 首先是解压缩:
tar xzvf hbase-1.0.1.1-bin.tar.gz cd hbase-1.0.1.1
此外还需要配置 JAVA 环境信息(如果你不是默认 Java 路径的话),修改目录 conf/hbase-env.sh 中的 JAVA_HOME 变量值为你的 Java 路径。conf/hbase-site.xml 内容,这是因为可以在下次启动时可以直接加载这些内容,以免系统重启时删除缓存文件。
<configuration > <property > <name > hbase.rootdir</name > <value > file:///home/user/hbase</value > </property > <property > <name > hbase.zookeeper.property.dataDir</name > <value > /home/user/zookeeper</value > </property > </configuration >
创建连接 首先,输入
启动 HBase 服务,如果提示 Permission Denied 请使用 sudo 权限或是进入 su 模式操作。接着输入
命令进行连接,连接成功后,即能进入HBase的命令行操作模式
输入 help 可以查看帮助菜单,现在你可以输入 whoami 指令查看当前的连接信息,得到结果user (auth:SIMPLE) groups: user
HTable操作 表的创建使用命令
create 'test' , 'cf1' , 'cf2' , 'cf3'
返回结果:
0 row(s) in 0.8070 seconds => Hbase::Table - test
使用list命令可以查看当前表的信息:
TABLE test 1 row(s) in 0.0880 seconds => ["test" ]
如果想要查看表的结构,使用describe命令
describe 'test' Table test is ENABLED test COLUMN FAMILIES DESCRIPTION {NAME => 'cf1' , DATA_BLOCK_ENCODING => 'NONE' , BLOOMFILTER => 'ROW' , REPLICATION _SCOPE => '0' , VERSIONS => '1' , COMPRESSION => 'NONE' , MIN_VERSIONS => '0' , TTL => 'FOREVER' , KEEP_DELETED_CELLS => 'FALSE' , BLOCKSIZE => '65536' , IN_MEMORY => 'false' , BLOCKCACHE => 'true' } {NAME => 'cf2' , DATA_BLOCK_ENCODING => 'NONE' , BLOOMFILTER => 'ROW' , REPLICATION _SCOPE => '0' , VERSIONS => '1' , COMPRESSION => 'NONE' , MIN_VERSIONS => '0' , TTL => 'FOREVER' , KEEP_DELETED_CELLS => 'FALSE' , BLOCKSIZE => '65536' , IN_MEMORY => 'false' , BLOCKCACHE => 'true' } {NAME => 'cf3' , DATA_BLOCK_ENCODING => 'NONE' , BLOOMFILTER => 'ROW' , REPLICATION _SCOPE => '0' , VERSIONS => '1' , COMPRESSION => 'NONE' , MIN_VERSIONS => '0' , TTL => 'FOREVER' , KEEP_DELETED_CELLS => 'FALSE' , BLOCKSIZE => '65536' , IN_MEMORY => 'false' , BLOCKCACHE => 'true' } 3 row(s) in 0.0660 seconds
使用put指令插入数据,并且插入成功则会有提示,如果语法错误,会有正确的格式提示。修改内容可以重复使用put,会以最后一次put结果为最终结果
put 'test' , 'row1' , 'cf1:a' , 'value1' 0 row(s) in 0.4560 seconds put 'test' , 'row1' , 'cf1:b' , 'value2' 0 row(s) in 0.0080 seconds put 'test' , 'row1' , 'cf2:aa' , 'value11' 0 row(s) in 0.0160 seconds put 'test' , 'row1' , 'cf3:aa' , 'value33' 0 row(s) in 0.0720 seconds put 'test' , 'row2' , 'cf3:aa' , 'value00' 0 row(s) in 0.0070 seconds put 'test' , 'row2' , 'cf2:bb' , 'valuez' 0 row(s) in 0.0090 seconds put 'test' , 'row3' , 'cf1:yy' , '1' 0 row(s) in 0.0130 seconds put 'test' , 'row3' , 'cf1:a' , '1' 0 row(s) in 0.0110 seconds put 'test' , 'row3' , 'cf1:a' , '2' 0 row(s) in 0.0090 seconds
使用scan命令查询一张表的内容:
scan 'test' ROW COLUMN+CELL row1 column=cf1:a, timestamp=1437727890775, value=value1 row1 column=cf1:b, timestamp=1437727903128, value=value2 row1 column=cf2:aa, timestamp=1437727922351, value=value11 row1 column=cf3:aa, timestamp=1437727934848, value=value33 row2 column=cf2:bb, timestamp=1437727960463, value=valuez row2 column=cf3:aa, timestamp=1437727948328, value=value00 row3 column=cf1:a, timestamp=1437727995468, value=2 row3 column=cf1:yy, timestamp=1437727983439, value=1 3 row(s) in 0.0850 seconds
如果你想要查询一个Key下的内容,对应地使用get指令:
get 'test' , 'row1' COLUMN CELL cf1:a timestamp=1437727890775, value=value1 cf1:b timestamp=1437727903128, value=value2 cf2:aa timestamp=1437727922351, value=value11 cf3:aa timestamp=1437727934848, value=value33 4 row(s) in 0.0570 seconds
如果你想要删除一张表,首先需要使用 disable 命令才能再使用 drop 命令,与 disable 对应的则是 enable 命令
disable 'test' 0 row(s) in 1.9220 seconds drop 'test' 0 row(s) in 0.2220 seconds
退出后,停止HBase服务:
./bin/stop-hbase.sh stopping hbase....................
本地伪分布式存储 请参照Apache HBase官方指导文档
Java API使用 这里使用 Eclipse,导入了 HBase 包下 lib 的所有 jar 作为依赖库。并且把hbase-site.xml 配置文件也放在工程目录下,此外你还需要 log4j.jar 包的支持。下面只是一个简单的创建表、插入数据、查询数据的示例
import java.io.IOException;import org.apache.commons.logging.Log;import org.apache.commons.logging.LogFactory;import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor;import org.apache.hadoop.hbase.KeyValue;import org.apache.hadoop.hbase.MasterNotRunningException;import org.apache.hadoop.hbase.TableName;import org.apache.hadoop.hbase.ZooKeeperConnectionException;import org.apache.hadoop.hbase.client.Admin;import org.apache.hadoop.hbase.client.Connection;import org.apache.hadoop.hbase.client.ConnectionFactory;import org.apache.hadoop.hbase.client.Get;import org.apache.hadoop.hbase.client.HTable;import org.apache.hadoop.hbase.client.Put;import org.apache.hadoop.hbase.client.Result;import org.apache.hadoop.hbase.client.ResultScanner;import org.apache.hadoop.hbase.client.Scan;import org.apache.hadoop.hbase.util.Bytes; public class Example private static Log logger = LogFactory.getLog(Example.class ) ; private static final String TABLE_NAME = "blog" ; private static final String CF_1 = "title" ; private static final String CF_2 = "author" ; private static final String CF_3 = "time" ; public static void createTables (Configuration config) throws IOException Connection connection = ConnectionFactory.createConnection(config); Admin admin = connection.getAdmin(); HTableDescriptor table = new HTableDescriptor(TableName.valueOf(TABLE_NAME)); table.addFamily(new HColumnDescriptor(CF_1)); table.addFamily(new HColumnDescriptor(CF_2)); table.addFamily(new HColumnDescriptor(CF_3)); logger.debug("Creating table." ); createOrOverwrite(admin, table); logger.info("Done." ); } private static void createOrOverwrite (Admin admin, HTableDescriptor table) throws IOException if (admin.tableExists(table.getTableName())) { admin.disableTable(table.getTableName()); admin.deleteTable(table.getTableName()); } admin.createTable(table); } public static void addTable (Configuration config) throws IOException HTable table =new HTable(config, Bytes.toBytes(TABLE_NAME)); Put put = new Put(Bytes.toBytes("demon" )); put.add(Bytes.toBytes(CF_1), Bytes.toBytes("givenName" ), Bytes.toBytes("John" )); put.add(Bytes.toBytes(CF_1), Bytes.toBytes("mi" ), Bytes.toBytes("M" )); put.add(Bytes.toBytes(CF_2), Bytes.toBytes("surame" ), Bytes.toBytes("Doe" )); put.add(Bytes.toBytes(CF_3), Bytes.toBytes("email" ), Bytes.toBytes("john.m.doe@gmail.com" )); table.put(put); table.flushCommits(); table.close(); } public static void modifyTable (Configuration config) throws IOException Connection connection = ConnectionFactory.createConnection(config); Admin admin = connection.getAdmin(); TableName tableName = TableName.valueOf(TABLE_NAME); if (admin.tableExists(tableName)) { System.out.println("Table does not exist." ); System.exit(-1 ); } } public static void queryAll (Configuration config) HTable table; Scan s = new Scan(); ResultScanner rs; try { table = new HTable(config, Bytes.toBytes(TABLE_NAME)); rs = table.getScanner(s); for (Result r:rs) { System.out.println("Scan: " +r); for (KeyValue keyValue : r.raw()) { System.out.println("列:" + new String(keyValue.getFamily()) + "====值:" + new String(keyValue.getValue())); } } } catch (IOException e) { e.printStackTrace(); } } public static void queryByRow (Configuration config) throws IOException HTable table = new HTable(config, Bytes.toBytes(TABLE_NAME)); Get get = new Get("demon" .getBytes()); Result rs = table.get(get); for (KeyValue kv : rs.raw()){ System.out.print(new String(kv.getRow()) + " " ); System.out.print(new String(kv.getFamily()) + ":" ); System.out.print(new String(kv.getQualifier()) + " " ); System.out.print("value: " +new String(kv.getValue())); System.out.println(" timestamp: " +kv.getTimestamp()); } } public static void main (String[] args) throws MasterNotRunningException, ZooKeeperConnectionException, IOException Configuration config = new Configuration(); config.addResource("hbase-site.xml" ); config = HBaseConfiguration.create(config); queryByRow(config); } }
运行结束后,使用 list 命令查看,发现新增了一张叫做 blog 的表。使用 scan命令查看,发现 blog 表中的确插入了名为 ‘demon’ 的一行数据。当然,也可以使用 java 的 API 来进行查询操作。而删除和 disable 则不再赘述,请参照 HBase Java API 内容,以及这个 官方API文档 。